


Agent Server handles checkpointing automatically
When using the Agent Server, you don’t need to implement or configure checkpointers manually. The server handles all persistence infrastructure for you behind the scenes.
Why use persistence
Persistence is required for the following features:- Human-in-the-loop: Checkpointers facilitate human-in-the-loop workflows by allowing humans to inspect, interrupt, and approve graph steps. Checkpointers are needed for these workflows as the person has to be able to view the state of a graph at any point in time, and the graph has to be able to resume execution after the person has made any updates to the state. See Interrupts for examples.
- Memory: Checkpointers allow for “memory” between interactions. In the case of repeated human interactions (like conversations) any follow up messages can be sent to that thread, which will retain its memory of previous ones. See Add memory for information on how to add and manage conversation memory using checkpointers.
- Time travel: Checkpointers allow for “time travel”, allowing users to replay prior graph executions to review and / or debug specific graph steps. In addition, checkpointers make it possible to fork the graph state at arbitrary checkpoints to explore alternative trajectories.
- Fault-tolerance: Checkpointing provides fault-tolerance and error recovery: if one or more nodes fail at a given superstep, you can restart your graph from the last successful step.
- Pending writes: When a graph node fails mid-execution at a given super-step, LangGraph stores pending checkpoint writes from any other nodes that completed successfully at that super-step. When you resume graph execution from that super-step you don’t re-run the successful nodes.
Core concepts
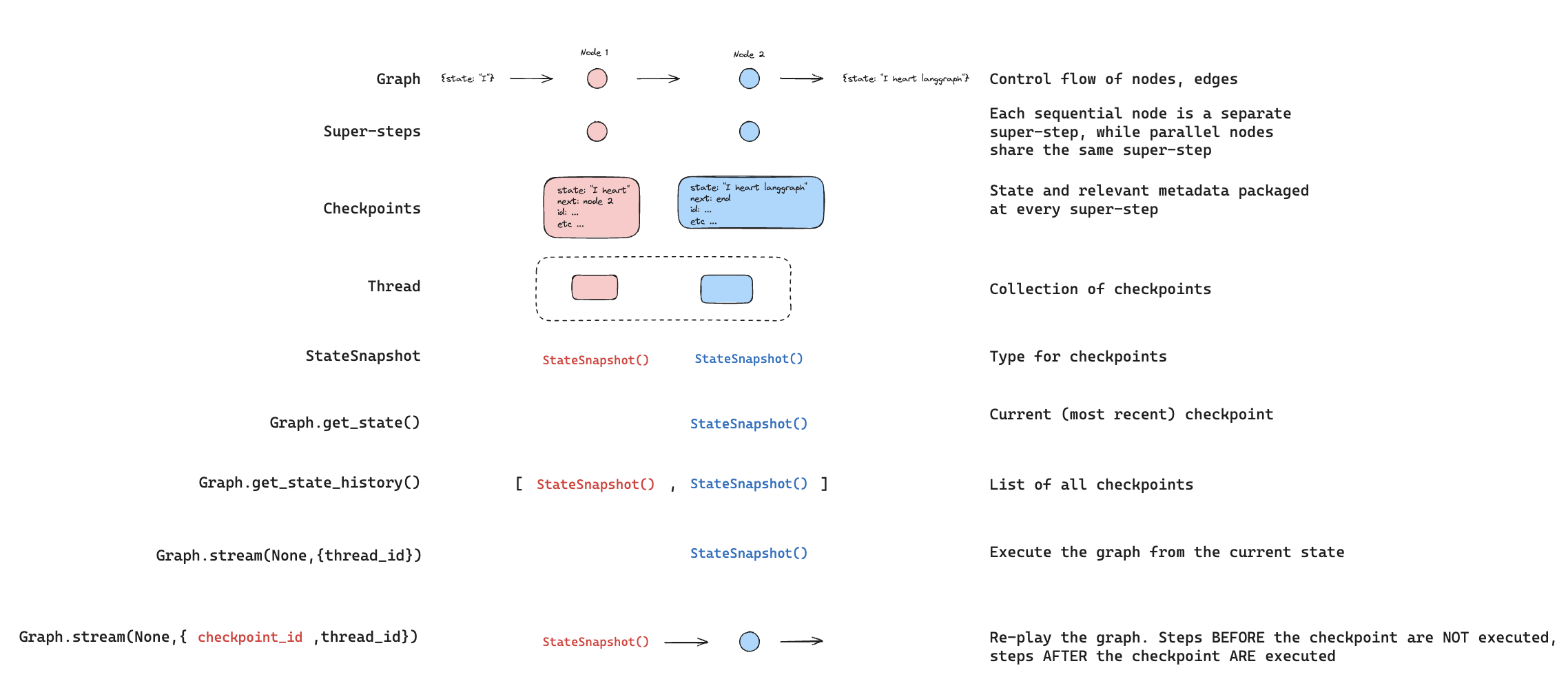
Threads
A thread is a unique ID or thread identifier assigned to each checkpoint saved by a checkpointer. It contains the accumulated state of a sequence of runs. When a run is executed, the state of the underlying graph of the assistant will be persisted to the thread. When invoking a graph with a checkpointer, you must specify athread_id as part of the configurable portion of the config:
thread_id as the primary key for storing and retrieving checkpoints. Without it, the checkpointer cannot save state or resume execution after an interrupt, since the checkpointer uses thread_id to load the saved state.
Checkpoints
The state of a thread at a particular point in time is called a checkpoint. A checkpoint is a snapshot of the graph state saved at each super-step and is represented by aStateSnapshot object (see StateSnapshot fields for the full field reference).
Super-steps
LangGraph created a checkpoint at each super-step boundary. A super-step is a single “tick” of the graph where all nodes scheduled for that step execute (potentially in parallel). For a sequential graph likeSTART -> A -> B -> END, there are separate super-steps for the input, node A, and node B — producing a checkpoint after each one. Understanding super-step boundaries is important for time travel, because you can only resume execution from a checkpoint (i.e., a super-step boundary).
Checkpoints are persisted and can be used to restore the state of a thread at a later time.
Let’s see what checkpoints are saved when a simple graph is invoked as follows:
- Empty checkpoint with
STARTas the next node to be executed - Checkpoint with the user input
{'foo': '', 'bar': []}andnodeAas the next node to be executed - Checkpoint with the outputs of
nodeA{'foo': 'a', 'bar': ['a']}andnodeBas the next node to be executed - Checkpoint with the outputs of
nodeB{'foo': 'b', 'bar': ['a', 'b']}and no next nodes to be executed
bar channel values contain outputs from both nodes as we have a reducer for the bar channel.
Checkpoint namespace
Each checkpoint has acheckpoint_ns (checkpoint namespace) field that identifies which graph or subgraph it belongs to:
""(empty string): The checkpoint belongs to the parent (root) graph."node_name:uuid": The checkpoint belongs to a subgraph invoked as the given node. For nested subgraphs, namespaces are joined with|separators (e.g.,"outer_node:uuid|inner_node:uuid").
Get and update state
Get state
When interacting with the saved graph state, you must specify a thread identifier. You can view the latest state of the graph by callinggraph.getState(config). This will return a StateSnapshot object that corresponds to the latest checkpoint associated with the thread ID provided in the config or a checkpoint associated with a checkpoint ID for the thread, if provided.
getState will look like this:
StateSnapshot fields
| Field | Type | Description |
|---|---|---|
values | object | State channel values at this checkpoint. |
next | string[] | Node names to execute next. Empty [] means the graph is complete. |
config | object | Contains thread_id, checkpoint_ns, and checkpoint_id. |
metadata | object | Execution metadata. Contains source ("input", "loop", or "update"), writes (node outputs), and step (super-step counter). |
createdAt | string | ISO 8601 timestamp of when this checkpoint was created. |
parentConfig | object | null | Config of the previous checkpoint. null for the first checkpoint. |
tasks | PregelTask[] | Tasks to execute at this step. Each task has id, name, error, interrupts, and optionally state (subgraph snapshot, when using subgraphs: true). |
Get state history
You can get the full history of the graph execution for a given thread by callinggraph.getStateHistory(config). This will return a list of StateSnapshot objects associated with the thread ID provided in the config. Importantly, the checkpoints will be ordered chronologically with the most recent checkpoint / StateSnapshot being the first in the list.
getStateHistory will look like this:

Find a specific checkpoint
You can filter the state history to find checkpoints matching specific criteria:Replay
Replay re-executes steps from a prior checkpoint. Invoke the graph with a priorcheckpoint_id to re-run nodes after that checkpoint. Nodes before the checkpoint are skipped (their results are already saved). Nodes after the checkpoint re-execute, including any LLM calls, API requests, or interrupts — which are always re-triggered during replay.
See Time travel for full details and code examples on replaying past executions.
Update state
You can edit the graph state usinggraph.updateState(). This creates a new checkpoint with the updated values — it does not modify the original checkpoint. The update is treated the same as a node update: values are passed through reducer functions when defined, so channels with reducers accumulate values rather than overwrite them.
You can optionally specify asNode to control which node the update is treated as coming from, which affects which node executes next. See Time travel: asNode for details.

Memory store
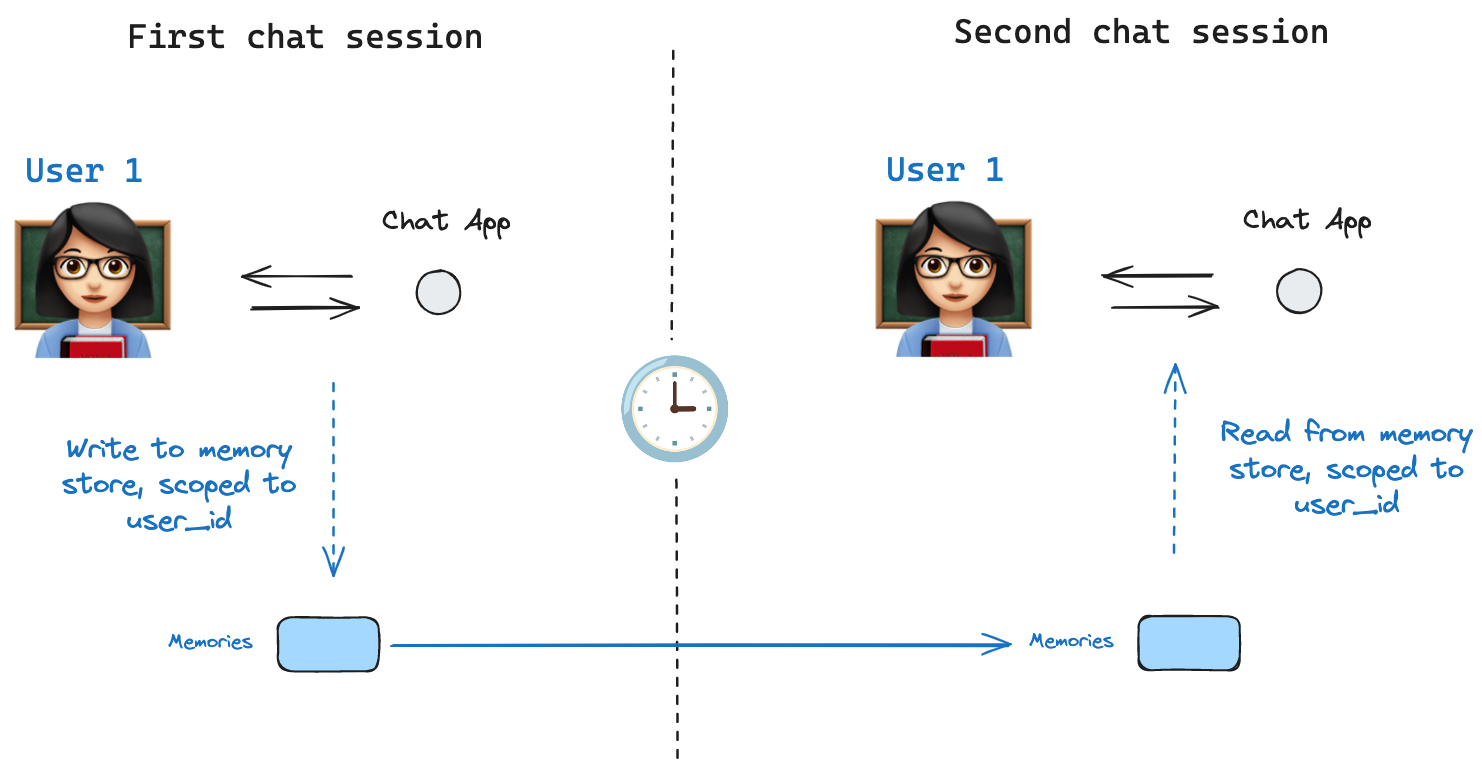
Store interface. As an illustration, we can define an InMemoryStore to store information about a user across threads. We simply compile our graph with a checkpointer, as before, and pass the store.
LangGraph API handles stores automatically
When using the LangGraph API, you don’t need to implement or configure stores manually. The API handles all storage infrastructure for you behind the scenes.
InMemoryStore is suitable for development and testing. For production, use a persistent store like
PostgresStore or RedisStore. All implementations extend BaseStore, which is the type annotation to use in node function signatures.Basic usage
First, let’s showcase this in isolation without using LangGraph.tuple, which in this specific example will be (<user_id>, "memories"). The namespace can be any length and represent anything, does not have to be user specific.
store.put method to save memories to our namespace in the store. When we do this, we specify the namespace, as defined above, and a key-value pair for the memory: the key is simply a unique identifier for the memory (memory_id) and the value (a dictionary) is the memory itself.
store.search method, which will return all memories for a given user as a list. The most recent memory is the last in the list.
-
value: The value of this memory -
key: A unique key for this memory in this namespace -
namespace: A tuple of strings, the namespace of this memory typeWhile the type istuple, it may be serialized as a list when converted to JSON (for example,['1', 'memories']). -
createdAt: Timestamp for when this memory was created -
updatedAt: Timestamp for when this memory was updated
Semantic search
Beyond simple retrieval, the store also supports semantic search, allowing you to find memories based on meaning rather than exact matches. To enable this, configure the store with an embedding model:fields parameter or by specifying the index parameter when storing memories:
Using in LangGraph
With this all in place, we use thememoryStore in LangGraph. The memoryStore works hand-in-hand with the checkpointer: the checkpointer saves state to threads, as discussed above, and the memoryStore allows us to store arbitrary information for access across threads. We compile the graph with both the checkpointer and the memoryStore as follows.
thread_id, as before, and also with a user_id, which we’ll use to namespace our memories to this particular user as we showed above.
userId in any node with the runtime argument. Here’s how you might use it to save memories:
store.search method to get memories. Recall the memories are returned as a list of objects that can be converted to a dictionary.
user_id is the same.
langgraph.json file. For example:
Checkpointer libraries
Under the hood, checkpointing is powered by checkpointer objects that conform toBaseCheckpointSaver interface. LangGraph provides several checkpointer implementations, all implemented via standalone, installable libraries:
@langchain/langgraph-checkpoint: The base interface for checkpointer savers (BaseCheckpointSaver) and serialization/deserialization interface (SerializerProtocol). Includes in-memory checkpointer implementation (MemorySaver) for experimentation. LangGraph comes with@langchain/langgraph-checkpointincluded.@langchain/langgraph-checkpoint-sqlite: An implementation of LangGraph checkpointer that uses SQLite database (SqliteSaver). Ideal for experimentation and local workflows. Needs to be installed separately.@langchain/langgraph-checkpoint-postgres: An advanced checkpointer that uses Postgres database (PostgresSaver), used in LangSmith. Ideal for using in production. Needs to be installed separately.@langchain/langgraph-checkpoint-mongodb: An advanced checkpointer that uses MongoDB database (@[MongoDBSaver]). Ideal for using in production. Needs to be installed separately.@langchain/langgraph-checkpoint-redis: An advanced checkpointer that uses Redis database (@[RedisSaver]). Ideal for using in production. Needs to be installed separately.
Checkpointer interface
Each checkpointer conforms to theBaseCheckpointSaver interface and implements the following methods:
.put- Store a checkpoint with its configuration and metadata..putWrites- Store intermediate writes linked to a checkpoint (i.e. pending writes)..getTuple- Fetch a checkpoint tuple using for a given configuration (thread_idandcheckpoint_id). This is used to populateStateSnapshotingraph.getState()..list- List checkpoints that match a given configuration and filter criteria. This is used to populate state history ingraph.getStateHistory()
Connect these docs to Claude, VSCode, and more via MCP for real-time answers.